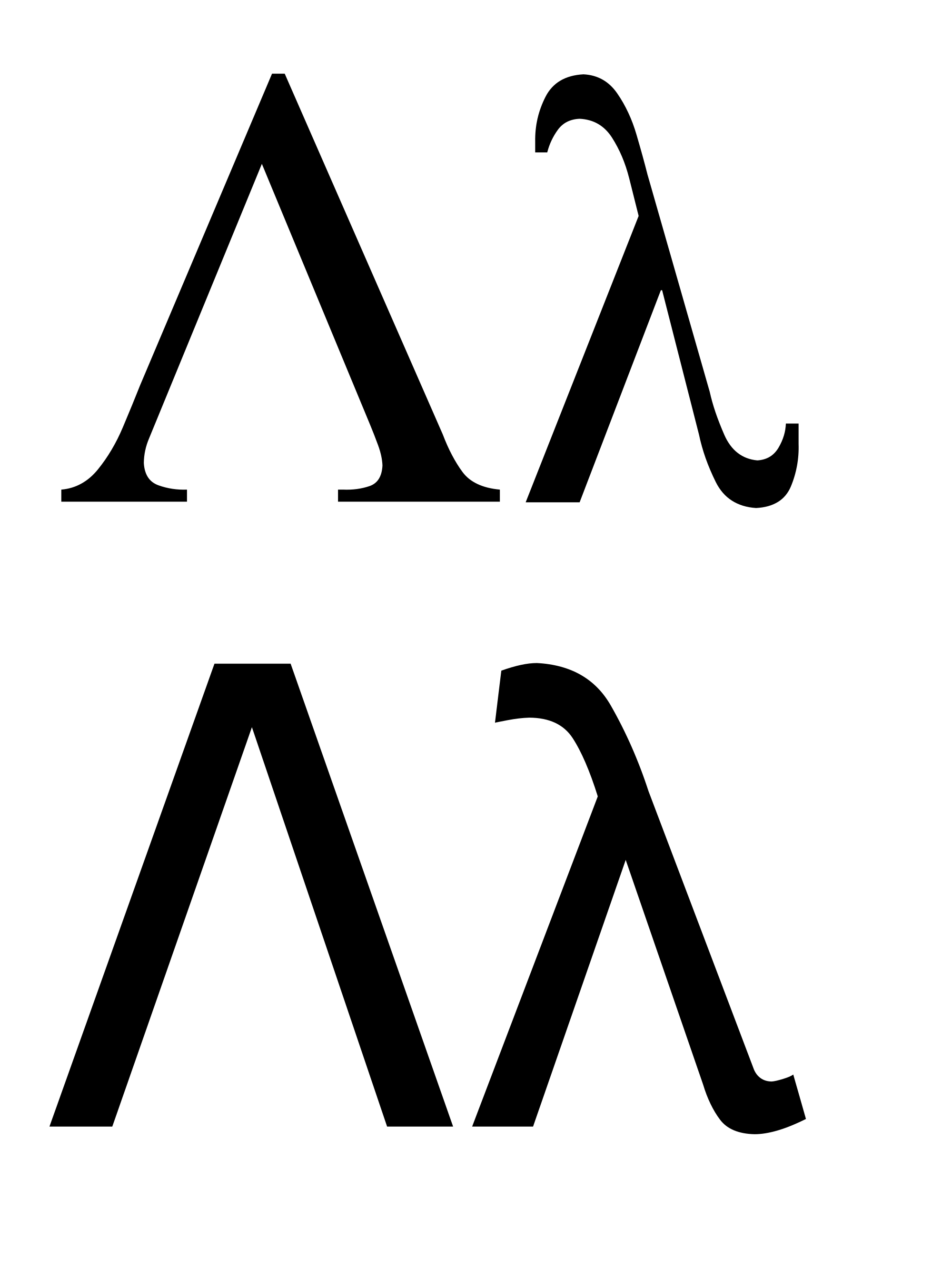I posted over a year ago I was working on a plugin version of HourGlass. I did get quite far with it, but I am not so sure anymore if I actually want to release it.
During last Autumn (2019) I got interested in VCV Rack and the modular synthesis way of working with sound. Which was a bit surprising because I used to hate all those patch cable systems, but VCV Rack somehow picked my interest. And now I just don’t seem to have that much interest at all in developing VST-type of plugins anymore.
Still, I suppose I could make a few more touches on the HourGlass plugin and release it “as it is” in the hopes it will be interesting or useful to some people. It would be something along the lines of an early beta-release that won’t get much support or updates in the future. Should it happen?
As if all the bullshit relating to Mac Os-X Catalina and the software notarization wasn’t already enough, the switch to the ARM architecture has sealed it. I now have 0% interest in making Apple-compatible software.
Of course, when I release open source software, anyone who is willing to pay all the Apple related expenses, can make them compatible, build them and distribute the binaries. (As long as the licenses are respected.) But I am no longer going to even think about it myself. I might release some binaries that will work in OS-X 10.13 (and maybe 10.14), but that’s the most I will do in the future and will also stop doing that once my already aged Mac laptop ceases working.
It looks like I just can’t give up working on HourGlass. 🙂 I was able to pick most of the sound processing parts from the stand alone application and make them work as a JUCE based plugin. The plugin is not going to be as full featured as the old stand alone application but hopefully it is also going to be a bit simpler to use. Not quite ready for even a beta release yet, but it shouldn’t take very long. (The video capture is from a stand alone application build of the plugin, but I’ve been testing the plugin version of it in Reaper, Ableton Live etc, it is as functional as the stand alone application build.)
OK, OK, I should work on λ, but argh…It’s just such a complicated thing. Some day, some day…
edit : 20th April 2019. I was able to get the VST2 development license in the end. So this blog post isn’t that relevant anymore.
I had to write at least one blog post for 2018…
And surprise, surprise, it’s bad news, of course. I will probably need to discontinue HourGlass, so if you are interested in it or have lost the download, you should get it now.
The reason for this is the Steinberg VST2 licensing situation. They are now determined to stop as many developers as possible from developing and distributing anything VST2 related. HourGlass hosts VST2 plugins, so it is under the Steinberg licensing terms. It looks like I was too late sending in my license application for them and it is not going to be accepted. I will wait for a while still, but if I don’t get a positive reply from them, I no doubt have to remove the HourGlass download links.
There is a chance I might look into making a new build of HourGlass that has the VST2 hosting removed. It’s not as simple as removing/disabling some code, however. Because 4 years have gone by since the last build, much has changed in the development frameworks and tools. I would for example need to update the code to use the Qt5 framework(*). I may not find it worth it going through all that trouble, especially if it was only to produce a version of the software that will just have a feature (the VST2 hosting) removed from it. But let’s see…
The situation also means I may have to discontinue the VST2 version of the PaulXStretch plugin soon. Also, if/when I get back to working on λ and if public builds of it appear, it will not be able to host and use VST2 plugins.
So, thanks a lot Steinberg! You sure seem to love VST3 very much and expect everyone else does too.
(*) Migrating to Qt5 wouldn’t really strictly be required, but it would be insane to use Qt4 anymore. Using Qt5 might even make the HourGlass GUI look and feel a bit nicer on macOs…
OK, so things have been rather quiet here in the blog. No news about λ and so on. I have been working on lots of different things, none of which have gotten to a state I would have liked to release to the public. This changed a bit some time ago when I decided it’s time to update the venerable Paul’s Extreme Time Stretch application.
I took out the old FLTK-based GUI code, the PortAudio code and the code that it used to use for reading and writing audio files and replaced all that with JUCE-based code. As I should have expected, it all turned out to be a pretty big project. But anyway, I finally managed to do something that I felt was worth releasing to the public for testing.
edit 23rd December 2016 : λ is not yet available for download, and no date yet…(It is still in a development stage where I’d have to release new binaries every day in order to deliver bug fixes and I have no streamlined solution for doing that…)
Since early 2015 I’ve been working every now and then on an application, now named λ, that was originally intended to be a modular GUI front-end for the Composer’s Desktop Project (CDP) command line programs. During the past few months I’ve started developing it more actively and it is becoming something larger. In addition to running the CDP programs, it now also hosts VST2/VST3/AU plugins and has some built-in processings too, among them a multilane sound sequencer/mixer. (I don’t want to call it “multitrack” because I don’t want to get stuck with some traditional notions about a DAW application…)
It resembles a modular patching environment like Max/MSP in that it has processing “nodes” or “objects” that can be connected together into a “patch” or a “graph”. However what makes λ a bit different is that each node always has some defined duration of audio or other data available and the nodes downstream can always randomly access all that data. So things like reverse playback or granular processing that “scans” the source audio in any direction/speed are possible no matter what the upstream nodes are doing. (For example the output of a reverb plugin can be reversed and so on.)
Why the weird name that is just the Greek lower case letter λ? Well, why not? 😉 However, if people don’t want to type that character, I am willing to tolerate them using “Lambda” or “lambda” instead. And if the name really becomes some kind of a problem, I may reconsider changing it.
Here are some YouTube videos demonstrating a bit what it can do :
At the moment λ is heavily based on offline processing the nodes into files on disk. However more responsive pseudo realtime processing can be added to some of the node types in the future. It will still however be mostly geared towards composers/sound designers who don’t necessarily need full realtime response, MIDI inputs, audio recording with monitoring etc. λ is not going to become a traditional DAW or even a traditional modular patching environment. There are plenty of those around already, so I don’t need to make one that tries to replicate ProTools, Reaper, Cubase, Max/MSP, Bidule and so on.
And then the question…Is HourGlass dead? It is. 😦 But wait… Not really. It will live on inside λ as a processing node. Currently the HourGlass node is not as comprehensive as the old Qt based application, but it will (re)develop as time goes on.
This month I’ve worked a bit on HourGlass 1.5. So there is still hope a public release will eventually happen. The multichannel/surround stuff sure has been a big mess to implement, with bugs and CPU performance problems popping up at every turn. However, with some private testing generously done byJean-Marc Duchenne with his extreme multichannel audio system (with dozens of channels and loudspeakers), some of the problems have been at least partially fixed.
The longer term plans definitely involve rewriting HourGlass from scratch, based on JUCE. Using the rather ancient Qt4 toolkit is beginning to feel quite miserable, but I will grudgingly persist in getting a few versions of HourGlass 1.5.x done with it for now.